Results & Implementation
This section details the performance of our custom DBSCAN implementation and visualizes the results on various datasets.
Algorithm Logic
Implementation follows the standard density-based clustering approach:
For each point, we find all neighbors within
epsradius using Euclidean distance.If a point has at least
min_samplesneighbors, it becomes a Core Point and starts a new cluster.Using a queue visit all density-reachable neighbors to expand the cluster.
Points that are not reachable from any Core Point are labeled as
-1(Noise).
Visual Results
We tested the algorithm on synthetic datasets that are notoriously difficult for distance-based algorithms like K-Means.
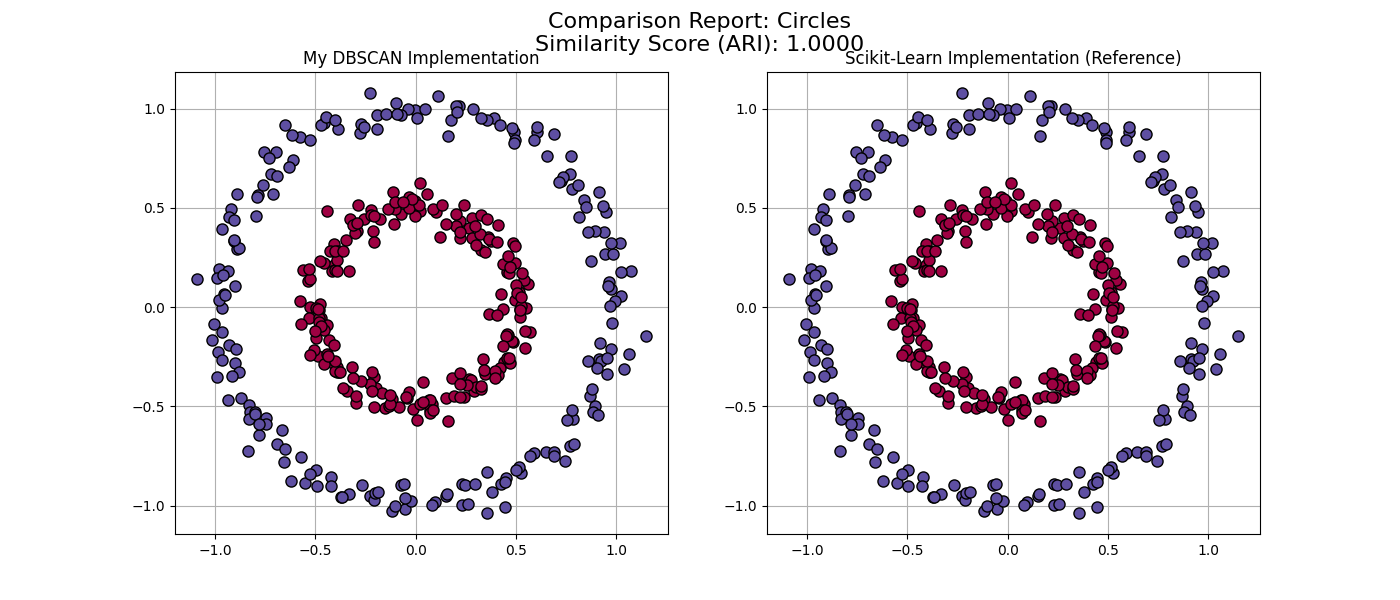
Moons Dataset
The “Moons” dataset consists of two interleaving half-circles. Standard K-Means would fail here by drawing a straight line through the middle. DBSCAN successfully follows the shape.
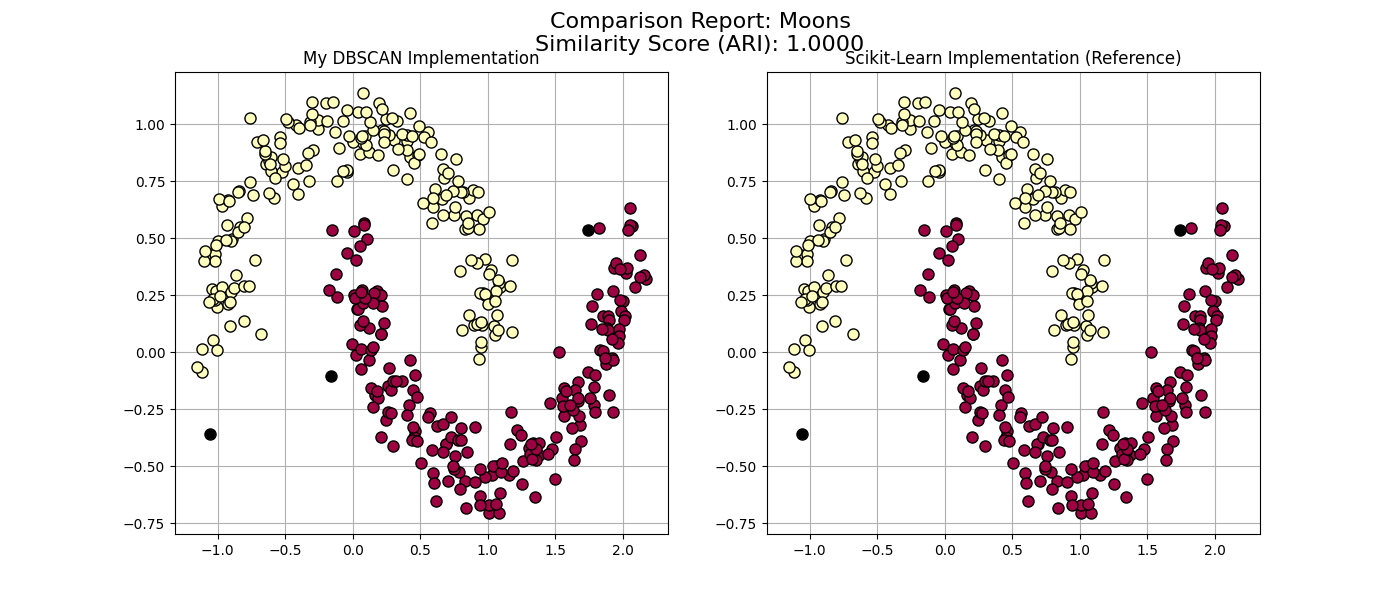
Circles Dataset
The “Circles” dataset contains a smaller circle inside a larger one. This is a classic topology problem.